
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- CodeEngn Basic 01
- 코드엔진 베이직
- malware
- 논문리뷰
- h4ckinggame
- 사회적 사실
- codeengn basic rce 01
- 디지털 포렌식 트랙
- 철학
- Best of the Best
- 에밀 뒤르켐
- BoB 12기
- CodeEngn Basic 5
- 코드엔진 basic 5
- 자살론
- bob
- BoB 12기 최종합격 후기
- 코드엔진
- 리버싱
- 사회분업론
- CodeEngn
- Today
- Total
woonadz :)
[개념정리]정렬_nabi 본문
컴퓨터 과학과 수학에서 정렬 알고리즘(sorting algorithm)이란 원소들을 번호순이나 사전 순서와 같이 일정한 순서대로 열거하는 알고리즘이다. 효율적인 정렬은 탐색이나 병합 알고리즘처럼 (정렬된 리스트에서 바르게 동작하는) 다른 알고리즘을 최적화하는 데 중요하다. 또 정렬 알고리즘은 데이터의 정규화나 의미있는 결과물을 생성하는 데 흔히 유용하게 쓰인다. 이 알고리즘의 결과는 반드시 다음 두 조건을 만족해야 한다.
1. 출력은 비 내림차순(각각의 원소가 전 순서 원소에 비해 이전의 원소보다 작지 않은 순서)이다.
2. 출력은 입력을 재배열하여 만든 순열이다.
-위키백과-
정렬이란 데이터를 일정한 규칙에 따라 재배열하는 것으로 오름차순 정렬과 내림차순 정렬이 있다.
위키백과에서 선택,삽입,버블 외에도 합병,퀵(사실 내가 소유하는 있는 컴퓨터 과학책에선 퀵 정렬을 재귀 알고리즘의 한 종류로 소개하고 있다. 이런것들을 보았을 때 중첩되는 개념들이 있어 굳이 정확히 나누는 게 의미가 있는 것 같진 않다.) 등 다양한 정렬 종류를 소개하고 있지만 이 블로그에선 가장 대표적인 선택, 삽입, 버블 정렬만을 소개하도록 하겠다. 대표적인 정렬 알고리즘들을 소개하기 전 왜 이렇게 많은 정렬 알고리즘이 있는지에 대한 의문이 든다.
다양한 정렬 알고리즘들의 쓰임
먼저 정렬 알고리즘이 다양한 이유는 간단하다. 각각의 알고리즘들의 장단점이 모두 다르기 때문이다. 따라서 사용자는 데이터의 특성에 알맞게 정렬 종류를 선택하면 된다.
단순한 선택과 삽입 정렬은 모두 작은 데이터에는 효울적이지만 큰 데이터에는 효율적이지 않다. 이유는 어떤 방식인지 알고나면 추측 가능할 것이다. (하나 하나 다 따져보아야 하니..) 삽입 정렬은 선택 정렬에 비해 데이터 비교를 적게 하고 성능이 좋아 더 선호된다. 하지만 선택 정렬은 쓰기를 삽입 보다 적게 하므로 쓰기 성능에 제약이 있는 경우 사용한다. (여기서 말하는 쓰기는 데이터의 위치를 바꾸는 그런 과정을 의미하는 듯 싶다.)
일반적으로 말하는 효율적인 정렬, 합병 정렬, 힙 정렬, 퀵 정렬 등은 실생활 데이터를 기준으로 랜덤 데이터에 효율적이다. < 첫째로, 이 알고리즘들이 일으키는 부하(시스템에서 원하는 효과를 얻기 위해 취하는 행동에 필요한 동작이나 자원)는 크기가 작은 데이터일수록 중대한 까닭에 하이브리드 알고리즘이 사용되기도 하며 데이터가 충분히 작으면 보통 삽입 정렬로 전환된다. 둘째로, 알고리즘은 이미 정렬된 데이터나 거의 정렬이 마무리된 데이터에 대해 성능이 떨어지는 경우가 있기 때문에 이 알고리즘들은 실생활 데이터에 일반화되어 있으며 대략적인 알고리즘들에 의해 O(n) 시간으로 정렬이 가능하다. 끝으로, 이 알고리즘들은 불안정 정렬에 속할 수 있는데 정렬 시 안정성은 바람직한 속성으로 간주되기도 한다. 그러므로 타임소트(합병 정렬 기반) 또는 인트로소트(퀵 정렬 기반으로, 필요 시 중간에 힙 정렬로 변경됨)와 같은 더 복잡한 알고리즘들이 적용되기도 한다. > - 위키백과
정렬의 종류
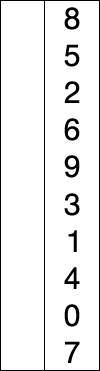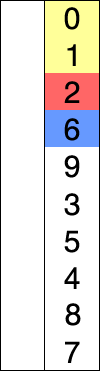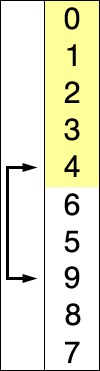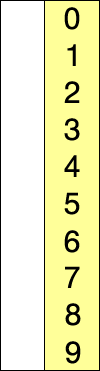
1. 선택 정렬 : 정렬되지 않은 데이터 중에서 가장 작은 데이터를 찾아 가장 앞의 데이터와 교환해나가는 방식의 알고리즘이다.
선택 정렬의 동작 과정
1. 데이터 집합에서 가장 작은 데이터를 찾는다.
2. 그 데이터를 가장 앞부터 순서대로 넣는다.
3. 이 과정을 반복한다.
말로는 이해하기 힘들것이다. 아래 그림을 보고 이해하도록 하자.
def selection(ds):
for a in range(0,len(ds)-1):
min_ind=a
for b in range(a+1, len(ds)):
if ds[b]<ds[min_ind]:
min_ind=b
ds[a], da[min_ind]=ds[min_ind], ds[a]
dataset = [2, 7, 4, 1, 9, 5]
selection(dataser)
print(dataset)
2. 삽입 정렬 : 아직 정렬되지 않은 임의의 데이터를 이미 정렬된 부분의 적절한 위치에 삽입해가며 정렬하는 방식이다.
삽입 정렬의 동작 과정
1. 맨 앞 데이터와 옆 데이터의 크기를 비교한다.
2. 데이터의 크기가 작은 쪽은 가장 앞으로 보낸다.
3. 맨 앞 데이터부터 3번째 데이터까지의 크기를 모두 비교한다.
4. 크기 순 대로 배열한다.
5. 이 과정을 반복
이 역시 말로는 이해하기 힘들것이다. 아래 그림을 보고 이해하도록 하자.

def insertion(ds):
for a in range(1, len(ds)):
key=ds[a]
b=a-1
while b>=0 and ds[b]>key:
ds[b+1]=ds[b]
b=b-1
ds[b+1]=key
dataset=[4,1,3,7,8,5,9]
insertion(dataset)
print(dataset)
3. 버블 정렬 : 서로 이웃한 데이터들을 비교해 가장 큰 데이터를 맨 뒤로 보내며 정렬하는 방식이다.
버블 정렬의 동작 과정
1. 맨 앞 데이터와 옆 데이터를 비교해 큰 데이터를 뒤로 보낸다.
2. 2번째 데이터와 3번째 데이터를 비교해 큰 데이터를 뒤로 보낸다.
3. 이 과정을 끝까지 반복
4. 끝까지 반복한 후 처음부터 다시 이 과정을 반복하지만 첫번째 반복 시점에서 가장 큰 데이터가 가장 뒤에 위치해있고 두번째 반복 시점에서 2번째로 큰 데이터가 뒤에서 2번째에 위치해 있다.(즉, 반복을 할 수록 뒤에서부터 하나씩 데이터를 비교할 필요가 없다.)
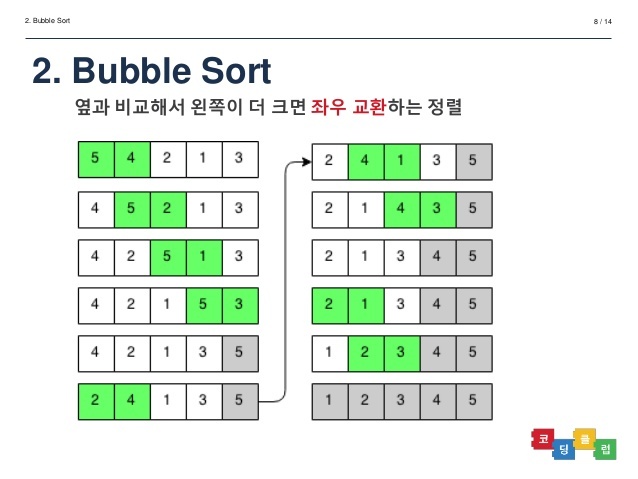
def bubble(ds):
for a in range(0, len(ds)-1):
for b in range(0, len(ds)-1-a):
if ds[b]>ds[b+1]:
ds[b], ds[b+1]=ds[b+1], ds[b]
dataset=[4,2,6,5,9,7,1]
bubble(dataset)
print(dataset)
끝인사 및 느낀점
알고리즘을 공부한지 3주 밖에 되지 않았지만 느낀 것이 있다. 알고리즘의 장단점, 특징들을 학습하고 상황에 따라 적용하는 능력은 중요하지만 무언가 정적으로? 틀에 박힌 공부를 할 필요는 없는 것 같다. 그러니까 꼭 알고리즘들을 구분을 지으려 하지 말고 '이 상황에서는 꼭 재귀만 써야해' 와 같은 마인드를 버리는 게 좋은 것 같다. 고등학교 때와는 다른 공부를 해야하는 것 같다.
대표 이미지 출처 : https://pixabay.com/ko/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=1653351">Pixabay로부터 입수된 https://pixabay.com/ko/users/200degrees-2051452/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=1653351">200 Degrees님의 이미지 입니다.
'IT > 자료구조 및 알고리즘' 카테고리의 다른 글
| [개념정리]백 트래킹_nabi (0) | 2021.11.16 |
|---|---|
| [개념정리]정수론 및 조합론_nabi (0) | 2021.11.08 |
| [개념정리]브루트 포스_nabi (0) | 2021.10.18 |
| [개념정리]재귀_nabi (0) | 2021.10.05 |
| 2021 KATABI 알고리즘스터디_계획서 (0) | 2021.10.01 |



