
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- race condition
- 프로그래머스
- 세마포어
- malware
- 정보보안기사
- BoB 12기
- dll side-loading
- 리버싱
- bob
- 논문리뷰
- DLL 사이드로딩
- h4ckinggame
- CodeEngn
- 코드엔진
- cve-2022-26923
- Best of the Best
- 정보기
- cve-2024-6387
- 필기
- Active Directory
- 디포전
- 디지털 포렌식 전문가 2급
- BoB 12기 최종합격 후기
- 디포전 2급
- 디지털 포렌식 트랙
- 뮤텍스
- Today
- Total
SEO
[heap basics] Tcache와 멀티스레딩 환경 속 Heap 메모리 관리 본문
멀티스레딩 환경에서 동적 메모리 할당의 변화
멀티스레딩 환경에서 효율적인 동적 메모리 할당은 성능에 중요한 영향을 미칩니다. 리눅스 초기에는 dlmalloc이라는 메모리 할당자를 사용했지만, 이후에 멀티스레딩 성능을 개선한 ptmalloc2로 대체되었습니다.
1. dlmalloc
- dlmalloc은 리눅스 초창기에 사용된 기본 메모리 할당자입니다.
- 여러 스레드가 동시에 malloc 함수를 호출하면, freelist라는 데이터 구조를 공유합니다.
- freelist : 사용 가능한 메모리 블록들의 목록
- 이 과정에서 하나의 스레드만 임계 영역에 진입하여 메모리를 할당받을 수 있으므로, 다른 스레드는 대기해야 합니다.
- 이러한 동작 방식은 멀티스레딩 환경에서 병목현상을 초래하고, 성능 저하로 이어지게 됩니다.
2. ptmalloc2
- ptmalloc2는 dlmalloc의 멀티스레딩 성능 문제를 해결하기 위해 개발되었습니다.
- 각 스레드가 독립적으로 메모리를 할당받을 수 있도록 per-thread arena 방식을 도입했습니다.
- Arena : 메모리를 효율적으로 관리하기 위한 힙과 관련된 구조체
- ptmalloc2의 특징:
- 여러 스레드가 동시에 malloc을 호출하더라도, 각 스레드에 할당된 별도의 힙과 freelist가 동작합니다.
- 따라서 임계 영역 충돌 없이 동시에 메모리를 할당할 수 있어 병목현상이 크게 줄어듭니다.
- 이 방식 덕분에 멀티스레딩 환경에서 성능이 크게 향상되었습니다.
| 특징 | dlmalloc | ptmalloc2 |
| 메모리 구조 | 공유된 freelist 사용 | 스레드별 arena로 독립적인 메모리 관리 |
| 동시 호출 처리 | 한 번에 하나의 스레드만 처리 가능 | 여러 스레드가 동시에 메모리 할당 가능 |
| 멀티스레딩 성능 | 성능 저하 발생 | 병목현상 감소, 높은 성능 |
Per-thread Arena 방식
Per-thread Arena 방식은 멀티스레딩 환경에서 동적 메모리 할당을 최적화하기 위한 메모리 관리 기법입니다. 이 방식은 각각의 스레드에 독립된 힙 영역과 관련 데이터 구조를 할당하여, 동시 호출 시 병목현상을 줄이는 데 중점을 둡니다.
1. Arena란 무엇인가?
- Arena는 메모리 할당 및 관리를 위해 예약된 힙 영역과 관련 데이터 구조의 묶음입니다.
- Arena는 메모리를 더 작은 단위로 나누고, malloc, free 같은 동적 메모리 관리 함수 호출 시 필요한 정보를 관리합니다.
- 멀티스레드 환경에서는 하나의 Arena를 여러 스레드가 공유하면 충돌이 발생하므로, Per-thread Arena 방식이 도입되었습니다.
2. Per-thread Arena의 동작 방식
- 스레드별 독립적인 Arena:
- 각 스레드에 독립적인 Arena가 할당되므로, 스레드가 서로 다른 Arena에서 작업하게 됩니다.
- Arena 할당 로직:
- 초기에는 한정된 수의 Arena가 생성됩니다.
- 새로운 스레드가 동작하면서 필요할 경우 추가 Arena를 동적으로 생성합니다.
- 일정한 수의 Arena가 생성된 후에는 Arena 재활용이 이루어집니다.
동작 방식 예시
- 기존 방식 (dlmalloc):
- 스레드 A와 B가 동시에 malloc 호출 → 하나의 Freelist를 공유하므로 스레드 A가 끝날 때까지 스레드 B는 대기
- Per-thread Arena 방식 (ptmalloc2):
- 스레드 A와 B가 각각 할당된 Arena에서 malloc 호출 → 각 Arena의 Freelist를 사용하므로 대기 없이 즉시 처리 가능
Bin 비교
Bin 종류 역할 대상 크기 관리 방식
| Unsorted Bin | 해제된 블록의 임시 저장 | 모든 크기 | FIFO 방식 |
| Tcache | 스레드 전용 캐싱, 빠른 메모리 할당 | 64KB 이하 | Per-thread 구조 |
| Fastbin | 매우 작은 크기의 메모리 빠르게 처리 | 64B~128B 이하 | 비정렬, 즉시 반환 가능 |
| Small Bin | 중간 크기의 메모리 관리 | 128B~512KB | 크기별 정렬 |
| Large Bin | 큰 크기의 메모리 관리 | 512KB 이상 | 크기별 정렬 |
Tcache (Thread Cache)
Tcache는 ptmalloc2에서 멀티스레딩 환경의 메모리 할당 성능을 최적화하기 위해 추가된 메커니즘입니다. 스레드별 독립적인 메모리 블록 캐싱을 통해 동기화 오버헤드를 제거합니다.
Tcache의 동작 방식
1. 캐싱 메커니즘
- Tcache의 역할:
- 크기가 작은 메모리 블록(tcache_max 이하)을 스레드별로 관리하여, 동일한 요청이 반복될 때 빠르게 처리되도록 합니다.
- 블록이 해제되면, 해당 블록은 Tcache의 캐시로 돌아가며, 이후 동일한 크기의 요청이 들어오면 캐시에 있는 블록을 즉시 반환합니다.
2. Tcache 구조
- Tcache는 각 스레드마다 독립적인 리스트를 가집니다.
- Tcache 리스트는 크기별로 관리되며, 특정 크기의 요청이 들어오면 해당 크기와 매핑된 리스트에서 블록을 가져옵니다.
- 각 크기에 대해 관리하는 블록의 최대 개수(tcache_count)가 정해져 있습니다. 기본값은 크기별로 7개입니다.
3. 동기화 없는 처리
- 전통적인 malloc과 달리, Tcache는 스레드별로 독립적이므로 동기화 락 없이 메모리를 할당하고 해제할 수 있습니다.
- 이는 다중 스레드 환경에서의 race condition을 방지하고, 성능을 크게 향상시킵니다.
Tcache의 내부 데이터 구조
Tcache는 다음과 같은 주요 구성 요소로 이루어져 있습니다:
- Tcache Bins:
- 크기별로 분리된 리스트로, 각 크기(bin)는 특정 메모리 블록 크기를 관리합니다.
- 예: bin[0]은 16바이트, bin[1]은 32바이트 블록 등을 관리.
- Tcache Entries:
- 각 bin에 연결된 메모리 블록의 리스트입니다.
- 연결 리스트로 구현되며, 가장 최근에 해제된 블록이 리스트의 맨 앞에 위치합니다.
- Per-thread 관리:
- 각 스레드가 독립적으로 Tcache 구조를 가지며, 이는 전역 동기화 필요성을 제거합니다.
Tcache의 주요 동작
- 메모리 할당:
- 요청 크기가 tcache_max 이하라면 Tcache를 먼저 확인합니다.
- Tcache에 적합한 블록이 있으면, 즉시 해당 블록을 반환합니다.
- 적합한 블록이 없다면, Unsorted Bin 또는 다른 Bin에서 블록을 가져옵니다.
- 메모리 해제:
- 해제된 블록은 먼저 Tcache에 반환됩니다.
- 만약 Tcache가 이미 가득 찬 상태라면, 블록은 Unsorted Bin으로 이동합니다.
Tcache와 다른 메모리 할당 방식 비교
| 특징 | Tcache | Unsorted | Fastbin |
| 관리 단위 | 스레드 전용 | 전역 | 전역 |
| 주요 목적 | 작은 크기의 빠른 메모리 할당 | 임시 저장 공간 | 매우 작은 크기의 빠른 할당/해제 |
| 동기화 필요 여부 | 필요 없음 | 필요 | 필요 |
| 성능 | 매우 빠름 | 중간 | 빠름 |
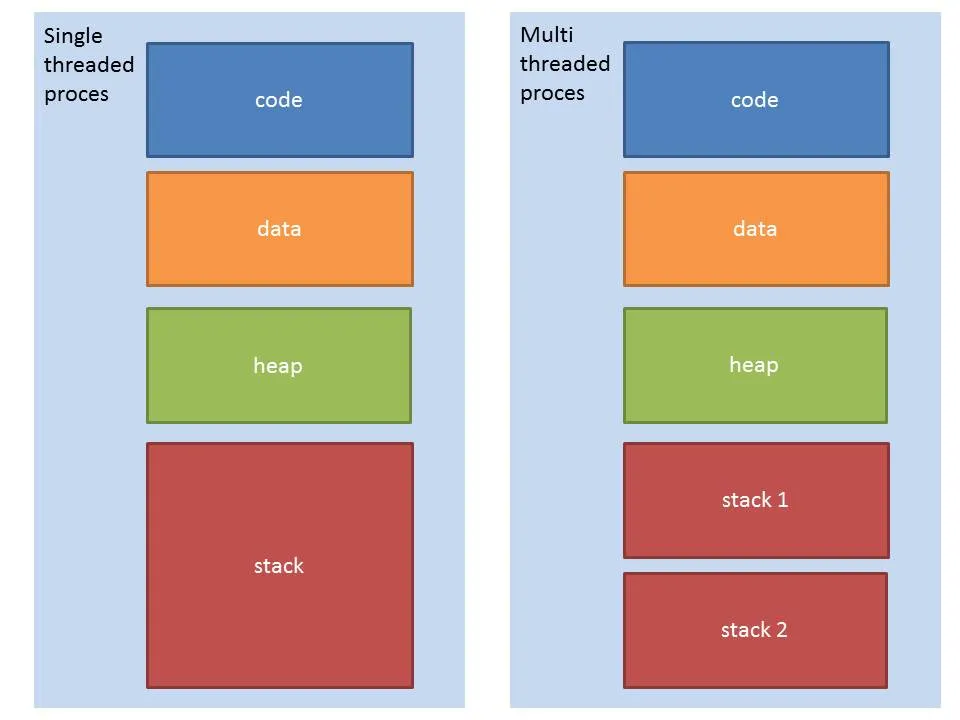
- 스레드는 프로세스 내에서 각 스레드별 스택을 따로 할당 받고, Code, Data, Heap 등의 영역은 공유합니다.
- Heap 영역을 공유한다는 말에서 제가 잘못 이해한 내용이 있었는데, Heap 영역을 공유한다는 것은 main thread의 heap 공간을 쪼개서 thread에 할당한다는 것이 아니라, 각 thread가 자신만의 arena를 가지고 메모리를 할당하는 방식입니다. 각 thread는 다음과 같은 특징이 있습니다.
- 독자적인 스택을 가지며, 이는 각 thread의 지역 변수와 함수 호출을 관리하는 데 사용됩니다.
- 자신만의 arena를 통해 힙 메모리를 관리합니다.
- arena는 메모리 할당을 관리하는 방식이며, 실제 할당된 메모리는 모든 thread가 접근할 수 있습니다.
- 스택을 제외한모든 세그먼트를 공유하지만, 다른 스레드의 스택 메모리도 접근 가능하긴 합니다. 하지만 이는 기술적으로 권장되지 않는 방식이어서 공유되는 데이터는 heap 등 공유하는 영역에 두는 것이 안전합니다.
https://stackoverflow.com/questions/1762418/what-resources-are-shared-between-threads
⇒ 아래 실습에서 어떤식으로 동작하는지 이해하실 수 있습니다.
brk와 mmap
brk와 mmap은 리눅스에서 메모리를 할당하는 시스템 콜입니다.
- brk
- 프로그램의 데이터 세그먼트를 나타내는 program break을 변경합니다.
- main 힙을 확장하거나 축소하는데 사용됩니다.
- 연속된 메모리 공간을 할당하고 주로 작은 크기의 메모리 할당에 사용됩니다.
- mmap
- 파일이나 장치를 메모리에 매핑하거나, 익명 메모리를 할당할 때 쓰입니다.
- 가상 메모리의 어느 위치에나 메모리를 할당할 수 있으며, 불연속적인 메모리 공간 할당이 가능합니다.
- 주로 큰 크기의 메모리 할당이나 스레드 arena 할당에 사용됩니다.
힙 동작 방식 확인하기
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int* thread1_memory;
void print_state(const char* message) {
printf("\\n=== %s ===\\n", message);
sleep(1);
}
void print_state_2(const char* message, int value) {
printf(message, value);
sleep(1);
}
void* thread_function(void* arg) {
int thread_num = *(int*)arg;
char msg[100];
sprintf(msg, "4. Thread %d created, before malloc", thread_num);
print_state(msg);
int* data = (int*)malloc(sizeof(int) * 100);
printf("Thread %d (ID: %ld) allocated memory at %p\\n",
thread_num, (long)pthread_self(), (void*)data);
if (thread_num == 1) {
thread1_memory = data;
*data = 42;
print_state_2("Thread 1 set value: %d\\n", *data);
} else {
print_state_2("Thread 2 reading Thread 1's memory: %d\\n", *thread1_memory);
}
sprintf(msg, "5. After malloc in thread %d, before free", thread_num);
print_state(msg);
free(data);
sprintf(msg, "6. After free in thread %d", thread_num);
print_state(msg);
return NULL;
}
int main() {
print_state("1. Before malloc in main thread");
int* data = (int*)malloc(sizeof(int) * 100);
printf("Main thread allocated memory at %p\\n", (void*)data);
print_state("2. After malloc in main thread, before free");
free(data);
print_state("3. After free in main thread");
pthread_t thread1, thread2;
int thread1_num = 1;
int thread2_num = 2;
pthread_create(&thread1, NULL, thread_function, &thread1_num);
pthread_create(&thread2, NULL, thread_function, &thread2_num);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
return 0;
}
gcc -g -o heap_analysis heap_analysis.c -pthread
제가 위 코드에서 gdb로 확인하고자 하는 내용은 다음과 같습니다.
- 코드에서 brk와 mmap을 언제 호출하는지
- thread1, thread2의 힙 메모리 접근
- 1~6단계의 메모리 상태 변화
1. main thread 생성
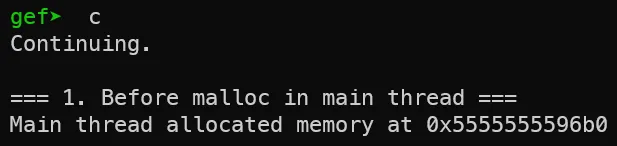
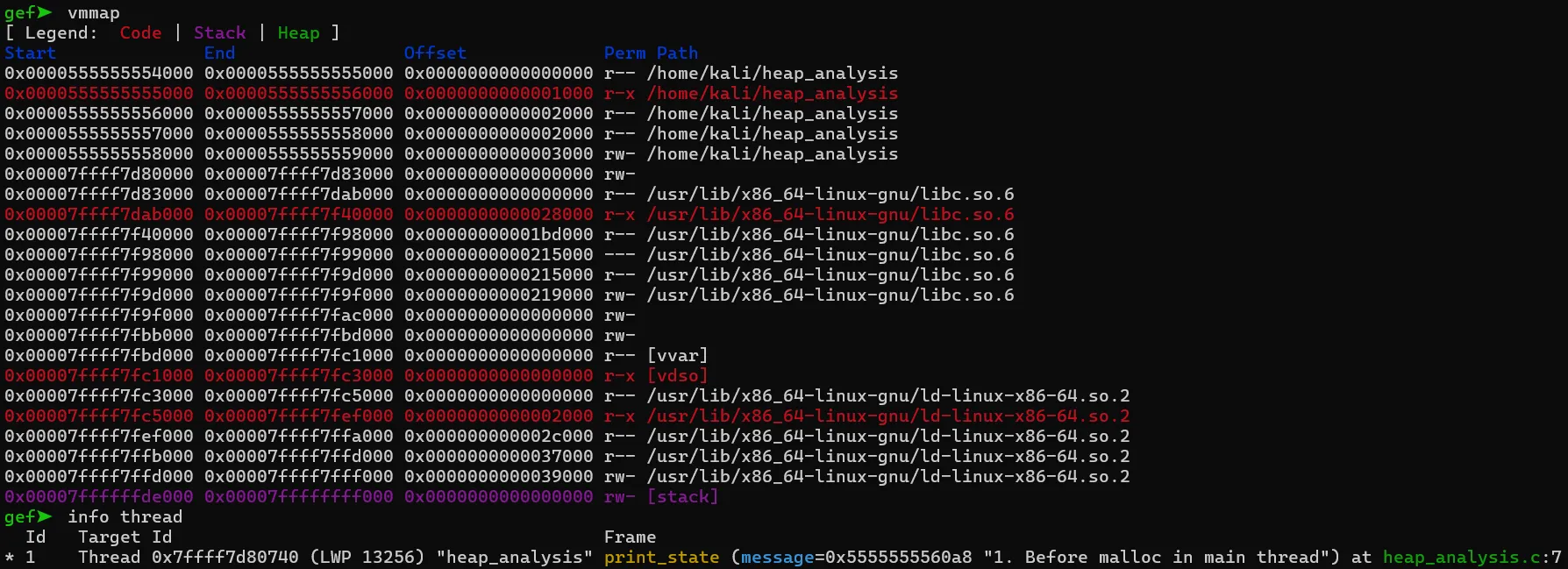
현재 main thread만 생성된 상태를 확인할 수 있습니다
2. main thread에서 힙 메모리 할당
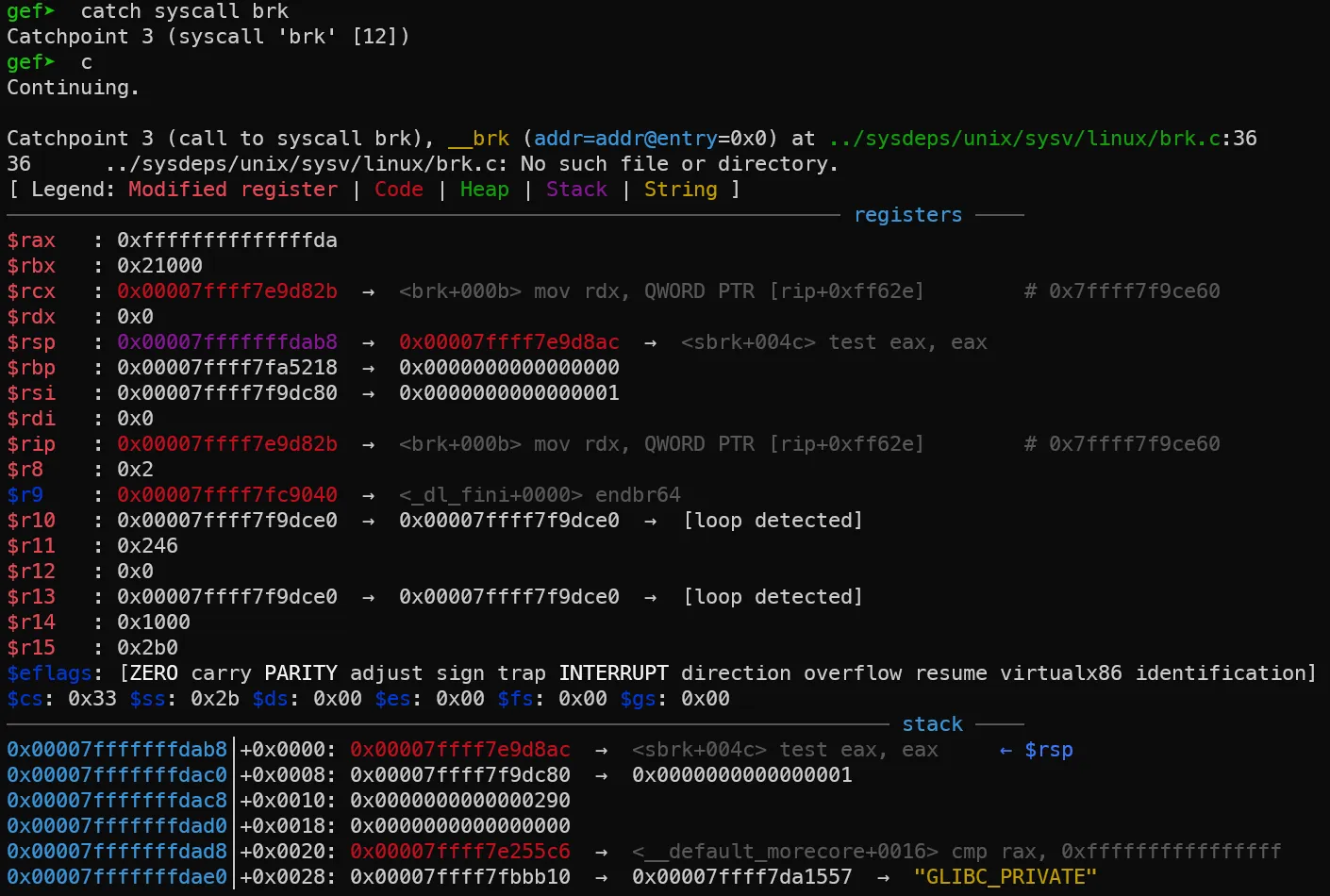
malloc을 호출하기 이전에 brk에 catch를 걸고 실행시키면, malloc 할당을 위해 brk syscall을 이용하는 것을 확인할 수 있습니다. main thread의 arena 할당을 위해 syscall을 호출합니다.
3. main thread에서 main arena 생성

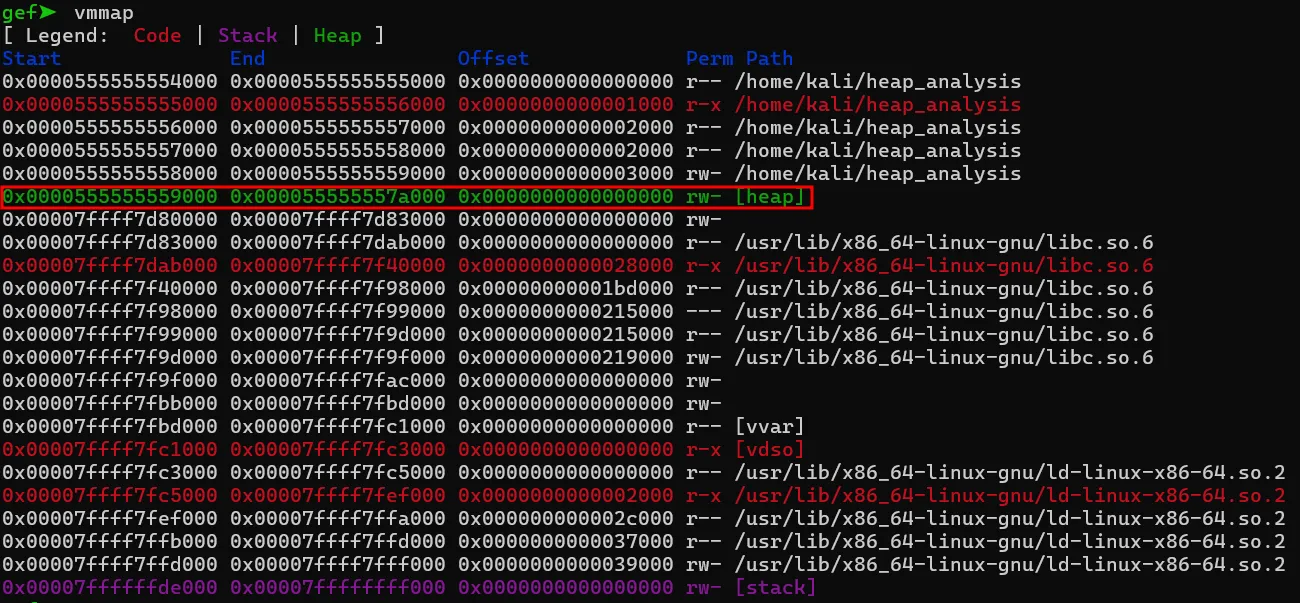

malloc을 호출한 이후 힙 공간이 생성된 것을 확인할 수 있습니다. 코드에서는 100바이트만 할당하였지만 0x21000바이트를 할당하였습니다. 요청된 공간보다 더 많은 공간을 할당하는 이유는 추가적인 malloc 요청 시에 이미 할당된 큰 블록을 활용하여 성능 최적화가 가능하기 때문입니다.
스레드에서 이후 추가로 malloc을 통한 메모리 할당이 있을 경우, 이 아레나에서 할당 가능한 공간을 찾아 공간을 할당합니다.
4. main arena에 대한 free 함수 호출
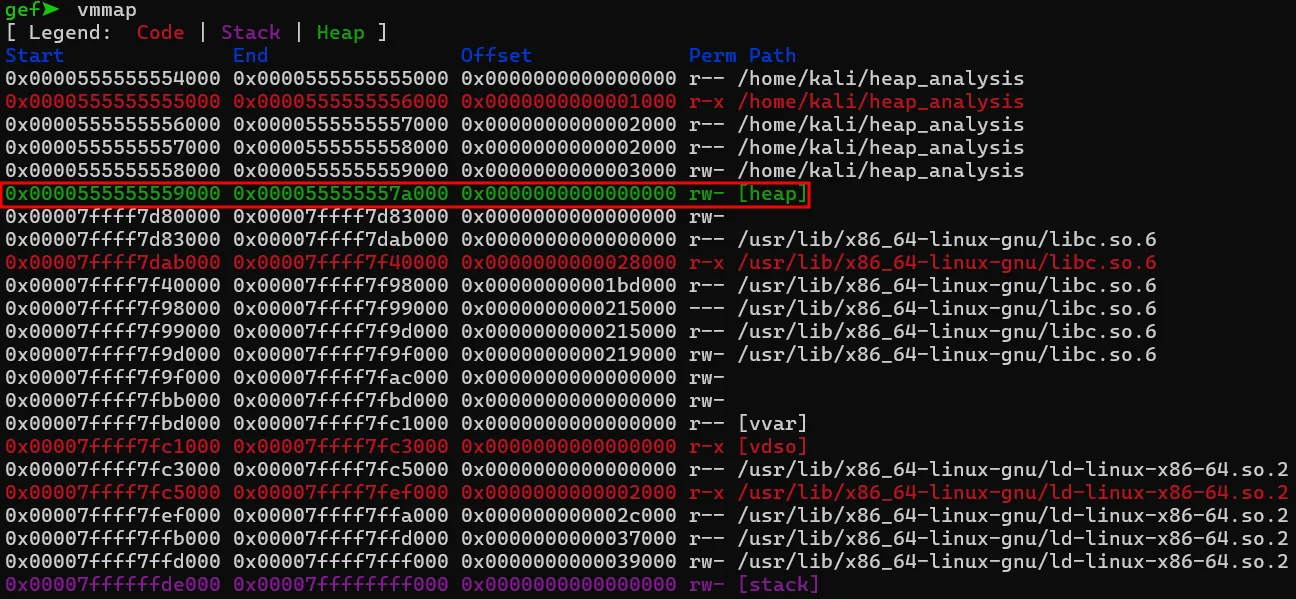

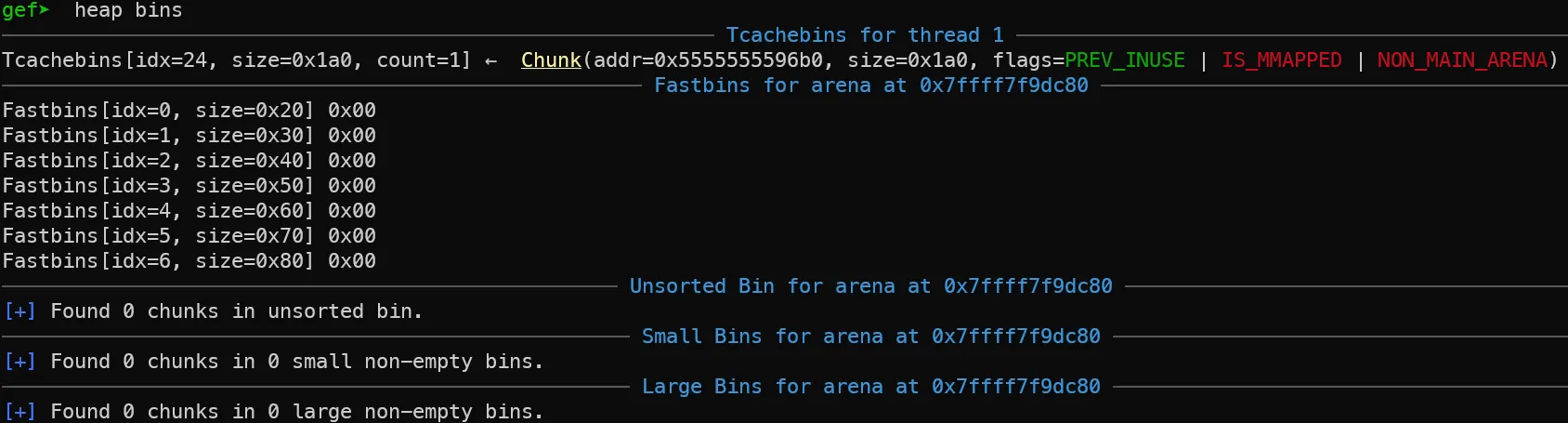
free 전 후의 메모리 변화를 비교해보면, free 이후에도 힙 공간이 남아있습니다. 즉, 메모리는 즉시 운영체제로 반환되지 않는다는 것을 알 수 있습니다. 대신에 free list에 추가되어 재사용 가능한 상태가 됩니다.
또한 청크 데이터 사이에 변화가 생겼습니다. free된 세번째 청크의 내용을 살펴보면 free list 관리를 위한 메타 데이터가 들어간 것을 학인할 수 있습니다. 즉, malloc으로 메모리가 할당되었을 때는 사용자 데이터를 저장하지만 free 되면 그 공간 중 일부를 free list 관리를 위한 메타데이터 저장공간으로 사용합니다.
5. thread 1,2 생성 및 malloc 호출 이전
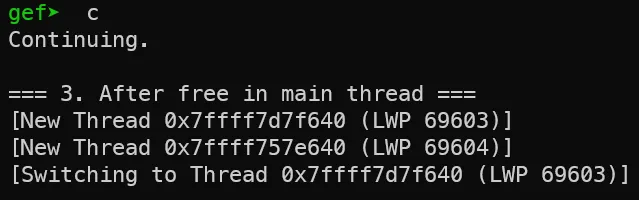
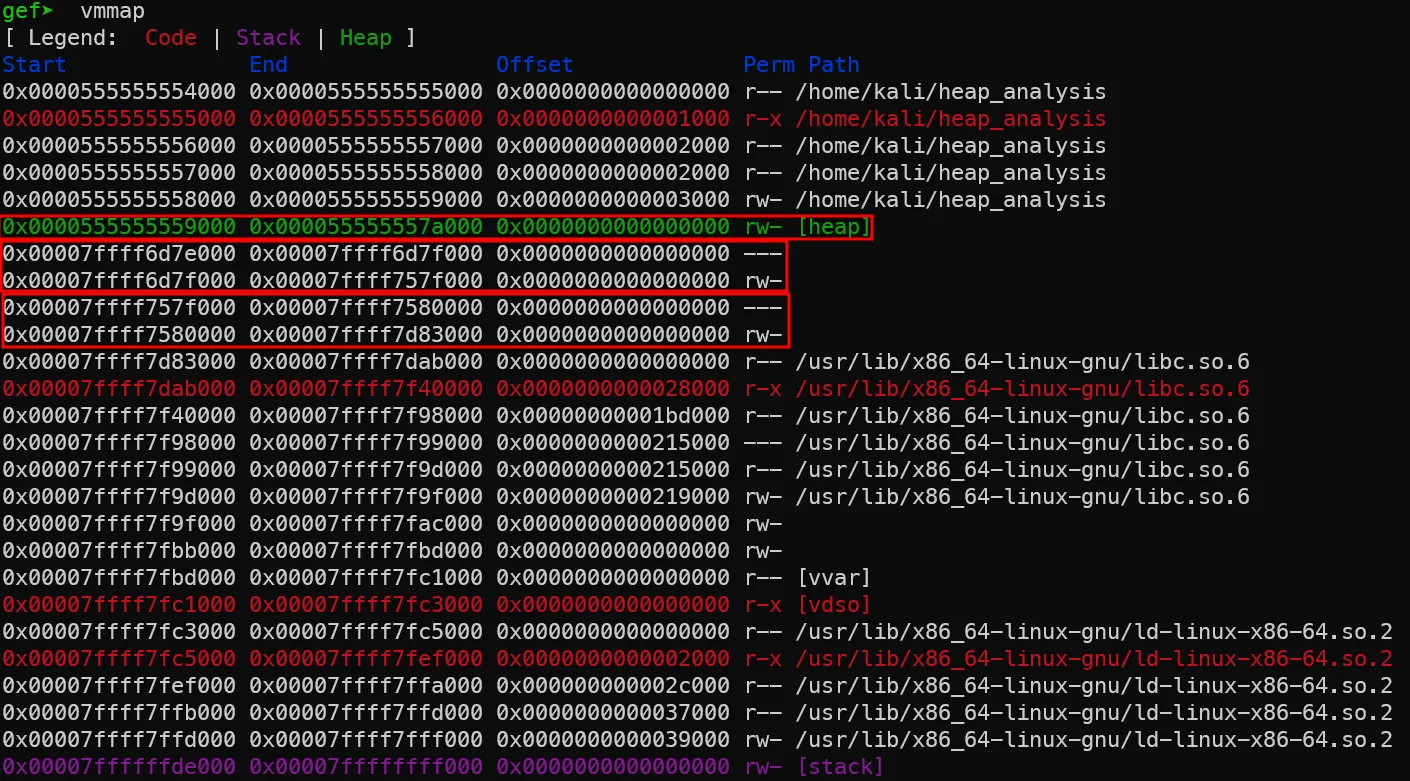

ID 값이 2와 3인 스레드 2개가 추가로 생성된 것을 확인할 수 있습니다. 또한 각각 ID 2,3 thread에 대한 스택이 할당된 것을 확인할 수 있습니다. 이 스택은 각 스레드에서만 접근 가능한 독립적인 공간입니다.
6. thread 1,2에서 힙 메모리 할당
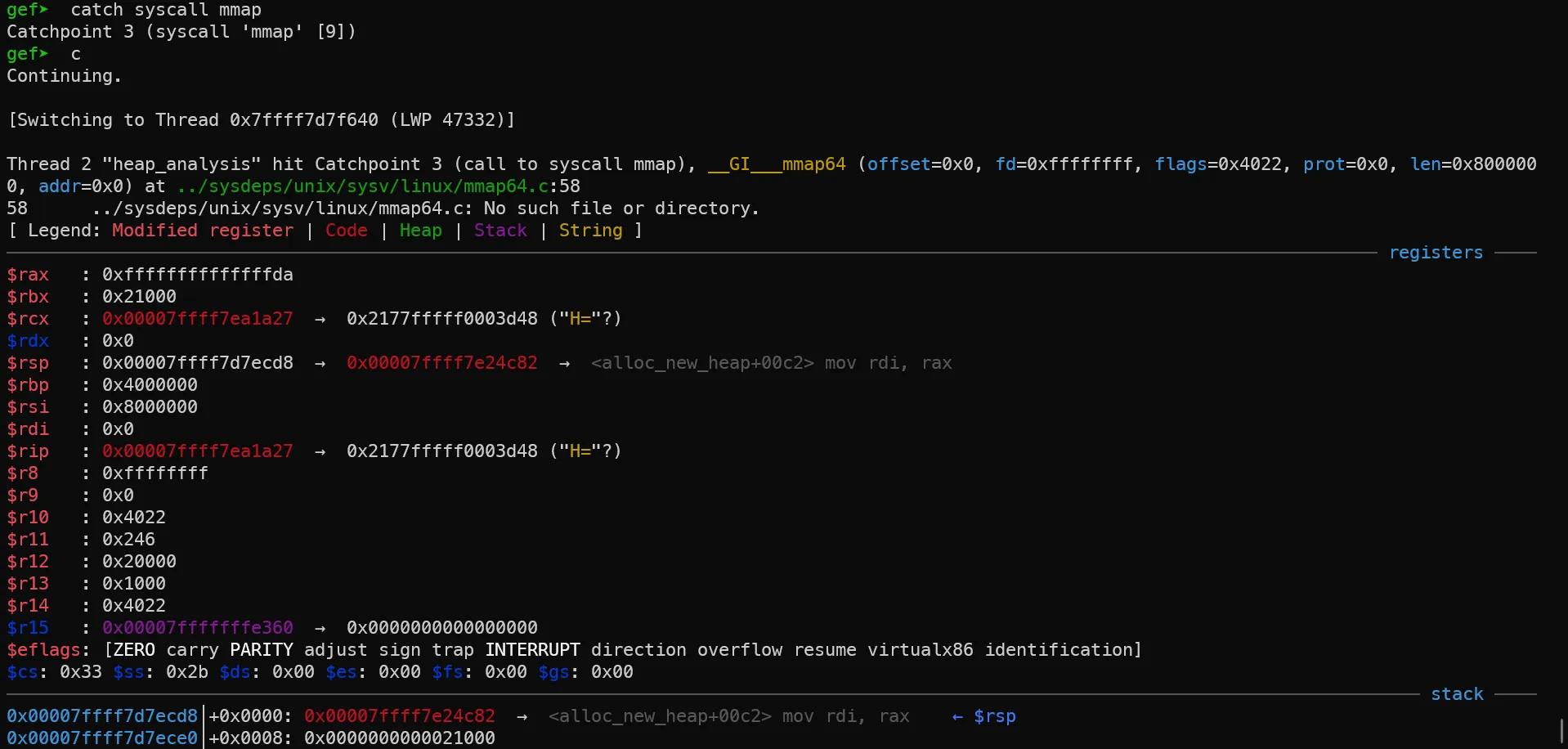
main thread와는 달리 mmap을 사용하여 힙이 생성됩니다. mmap을 사용하여 커널에 메모리 할당을 요청하는 것을 확인할 수 있습니다.
7. thread 1,2에서 thread arena 생성
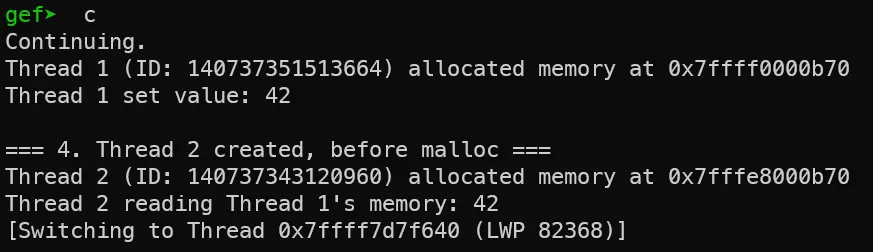
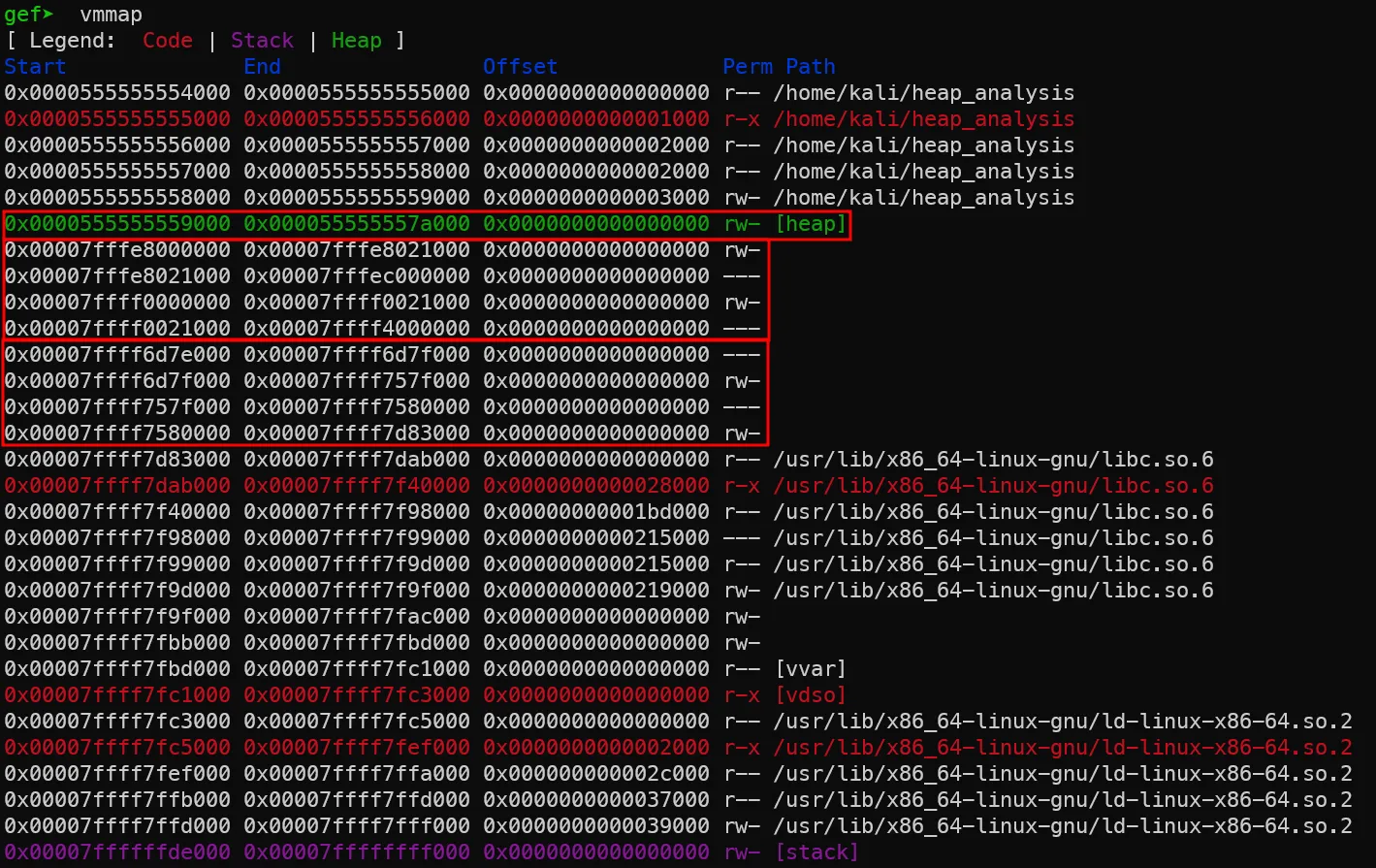
thread 1,2의 스택 공간 아래로 힙 공간이 생성되었습니다. 이 힙은 각 스레드가 서로 공유할 수 있는 공간으로, 접근 가능하여 읽고 쓸 수 있습니다.
실제 위 코드의 출력값을 확인하시면 thread 1의 힙 공간에 쓰인 42라는 값을 thread 2에서 읽어서 출력하는 것을 보실 수 있습니다.
8. thead 1,2 arena에 대한 free 함수 호출
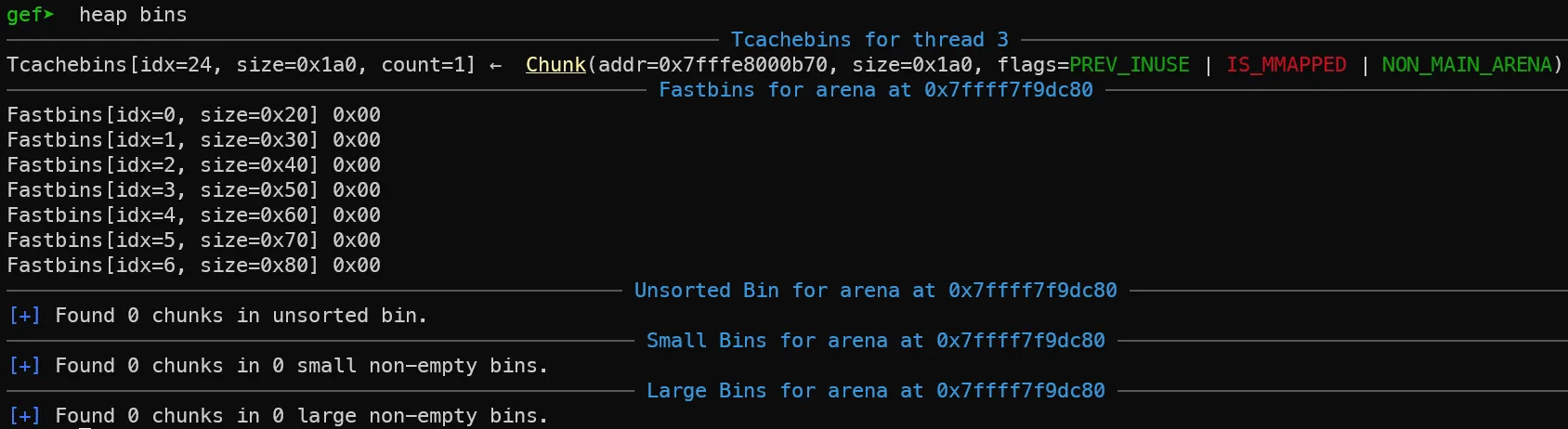
free 함수 호출 시에 Tcachebins로 청크가 옮겨진 것을 확인할 수 있습니다.
참고 문헌
https://blog.naver.com/njuhb/220994563346
https://wogh8732.tistory.com/178
https://elixir.bootlin.com/glibc/glibc-2.26/source/malloc/malloc.c
malloc.c - malloc/malloc.c - Glibc source code glibc-2.26 - Bootlin Elixir Cross Referencer
/ malloc / malloc.c /* Malloc implementation for multiple threads without lock contention. Copyright (C) 1996-2017 Free Software Foundation, Inc. This file is part of the GNU C Library. Contributed by Wolfram Gloger and Doug Lea , 2001. The GNU C Library i
elixir.bootlin.com
힙 어렵네요... 아직도 헷갈리고 의문이 풀리지 않는 부분이 있어서 해결하면 또 정리해서 올리도록 하겠습니다.,,
'Security > System' 카테고리의 다른 글
| [OS] Race Condition과 세마포어/뮤텍스 (0) | 2025.03.24 |
|---|---|
| [heap exploit] ptmalloc2의 unsorted bin과 Top Chunk (0) | 2025.01.12 |
| [heap exploit] Use-After-Free (UAF) 취약점 (0) | 2025.01.12 |
